幾何分布
初めて成功するまでに何回の試行が必要かをモデル化する幾何分布を学びます。無記憶性の意味と、実務での使いどころを解説します。
難易度 Lv 3 / 10想定時間:約20分
できるようになること
- 幾何分布の前提を確認し、使えるかどうかを判断できる
- P(X=k)=(1−p)k−1p を使って確率を計算できる
- 無記憶性の意味を説明できる
不良品はいつ見つかるか
ある工場で、製品を1個ずつ検査していきます。不良品率は5%です。
二項分布では「100個のうち何個が不良か」を考えました。試行回数が n=100 と決まっていて、その中の成功回数を数えます。
ここでは問いが変わります。「何個目で初めて不良品が見つかるか」です。
今度は試行回数が決まっていません。1個目で見つかるかもしれないし、50個目かもしれません。「初めて成功するまでの試行回数」を確率変数として扱う分布が**幾何分布(**geometric distribution)です。
なお、幾何分布では「目的の事象が起きること」を慣習的に「成功」と呼びます。今回は「不良品を見つけること」が検査の目的なので、不良品の発見が「成功」にあたります。
幾何分布とは何か
1回の試行で成功確率が p のベルヌーイ試行(結果が「成功」か「失敗」の2択で、成功確率が毎回同じ独立な試行)を繰り返し、初めて成功するまでの試行回数を確率変数 X とします。
この X が幾何分布に従うとき、次のように書きます。
X∼Geo(p)
X は1以上の整数値をとります(最低でも1回は試行が必要なため)。
幾何分布には「初めて成功するまでの試行回数」(X=1,2,3,…)と「初めて成功するまでの失敗回数」(X=0,1,2,…)の2通りの定義があります。教科書やソフトウェアによって異なるため、どちらを使っているかを必ず確認してください。本単元では 試行回数 の定義を使います。
二項分布との違い
幾何分布と二項分布はどちらもベルヌーイ試行に基づきますが、何が固定で何が変数かが異なります。
| 二項分布 B(n,p) | 幾何分布 Geo(p) |
|---|
| 固定するもの | 試行回数 n | 成功回数(1回) |
| 確率変数 | 成功回数 X | 試行回数 X |
| 問い | n 回中、何回成功するか | 初めて成功するまで何回かかるか |
幾何分布が成り立つための前提
幾何分布を使うためには、二項分布と共通する前提が必要です。
| 前提 | 意味 | 検査の例 |
|---|
| 1. 結果は2択 | 各試行の結果が「成功/失敗」の2種類だけ | 不良品(成功)/良品(失敗) |
| 2. 成功確率が一定 | どの試行でも成功確率が p で変わらない | どの製品も不良品になる確率が5% |
| 3. 独立 | ある試行の結果が他の試行の確率に影響しない | ある製品の良否が次の製品に影響しない |
二項分布では「試行回数が固定」という前提がありましたが、幾何分布では試行回数そのものが確率変数なので、この前提は不要です。
前提が怪しいときの確認ポイント
前提1:成功/失敗の2択に整理できているか
検査結果が「良品・要修正・不良品」のように3段階以上ある場合、そのままでは2択になりません。目的に合わせて「成功」を定義し直し、2択にできるかを検討します。
前提2:成功確率 p は途中で変わっていないか
製造ラインが長時間稼働すると不良率が上がることがあります。この場合、初期に検査する製品と後半の製品で p が異なるため、幾何分布の前提が崩れます。
ロットや時間帯ごとに不良率を確認し、p が安定しているかを検証します。
前提3:独立だと言える根拠はあるか
同じ素材ロットから作られた製品は、1つに欠陥があると他にも欠陥が出やすいことがあります。こうした場合、試行間に依存関係があり、独立の前提が怪しくなります。
試行間に共通の要因がないかを確認します。
幾何分布の確率計算
前提が成り立つとき、k 回目に初めて成功する確率は次の式で計算できます。
P(X=k)=(1−p)k−1p(k=1,2,3,…)
各項の意味は次のとおりです。
- (1−p)k−1:最初の k−1 回がすべて失敗する確率
- p:k 回目に成功する確率
前提3(独立)より、各試行の確率を掛け合わせることができます。そのため「k−1 回連続で失敗」と「k 回目に成功」の確率の積で表せます。
成功確率 p の値によって、分布の形が変わります。
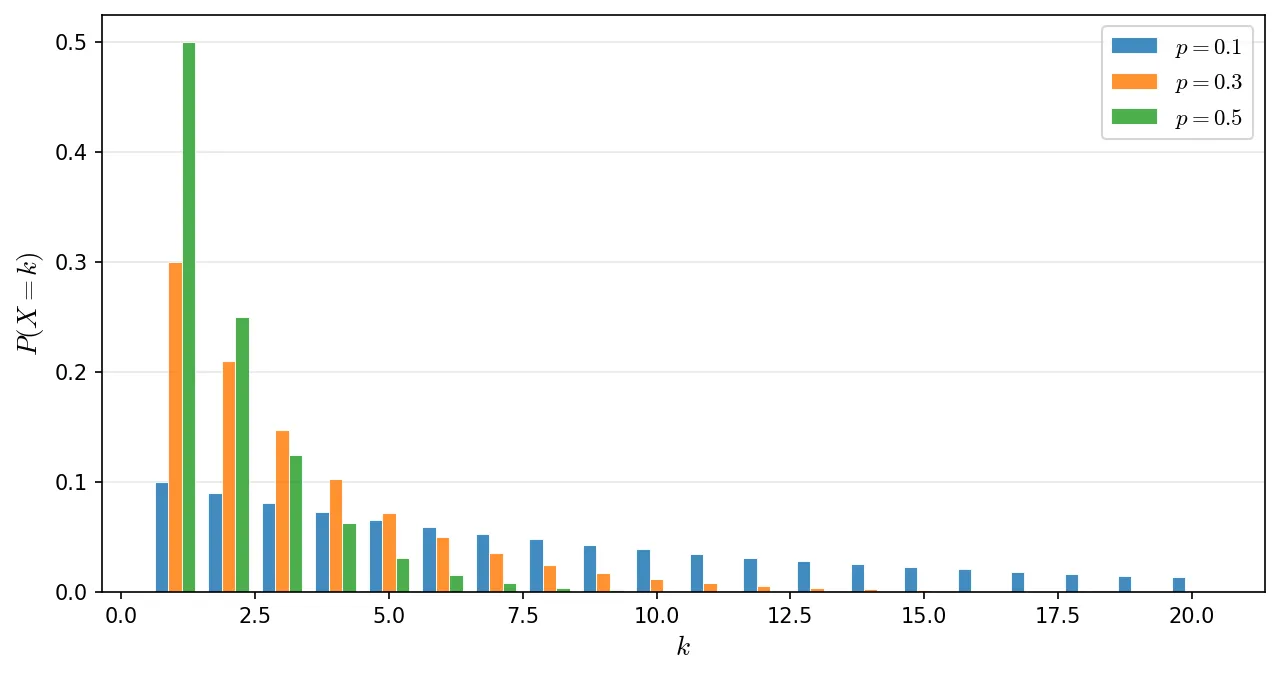
k=1 のとき(1回目で成功)が最も確率が高く、k が大きくなるほど確率は減少します。p が大きいほど早い段階に集中し、p が小さいほどなだらかに減少していきます。
例:不良品率 p=0.05 のとき、ちょうど3個目で初めて不良品が見つかる確率は、
P(X=3)=(1−0.05)3−1×0.05=0.952×0.05=0.045125
例:p=0.2 のとき、何回目が起こりやすいか
p=0.2 のとき、各 k の確率を並べます。
| k | 1 | 2 | 3 | 4 | 5 | 6 |
|---|
| P(X=k) | 0.2000 | 0.1600 | 0.1280 | 0.1024 | 0.0819 | 0.0655 |
確率の合計は1になるか
確率質量関数を k=1 から ∞ まで足すと、
∑k=1∞P(X=k)=∑k=1∞(1−p)k−1p=p∑k=0∞(1−p)k
0<p≤1 のとき ∣1−p∣<1 なので、等比級数の公式より、
p⋅1−(1−p)1=p⋅p1=1
となり、確率の合計が1であることが確認できます。
期待値と分散
X∼Geo(p) のとき、
- 期待値:E[X]=p1
- 分散:Var(X)=p21−p
例:不良品率が5%(p=0.05)なら、初めて不良品が見つかるまでの平均回数は 0.051=20 回です。直感的にも「20個に1個の割合なら、平均20個で見つかる」と納得できます。
期待値の導出
E[X]=∑k=1∞k(1−p)k−1p=p∑k=1∞k(1−p)k−1
ここで、等比級数の和の公式 k=0∑∞rk=1−r1 を r で微分すると得られる k=1∑∞krk−1=(1−r)21(∣r∣<1)を使うと、
=p⋅(1−(1−p))21=p⋅p21=p1
分散の導出
E[X(X−1)] を求めます。
E[X(X−1)]=∑k=1∞k(k−1)(1−p)k−1p=p(1−p)∑k=2∞k(k−1)(1−p)k−2
k=2∑∞k(k−1)rk−2=(1−r)32 を使うと、
=p(1−p)⋅p32=p22(1−p)
E[X2]=E[X(X−1)]+E[X]=p22(1−p)+p1=p22(1−p)+p=p22−p
Var(X)=E[X2]−(E[X])2=p22−p−p21=p21−p
無記憶性
幾何分布には**無記憶性(**memorylessness)という特別な性質があります。
「すでに s 回失敗した後、さらに t 回以上かかる確率」は、「最初から t 回以上かかる確率」と同じになります。
P(X>s+t∣X>s)=P(X>t)
具体例:不良品率5%の検査で、19個調べても不良品が見つかりませんでした。「あと5個以内に見つかる確率」は、最初から「5個以内に見つかる確率」と変わりません。
「もう19個も調べたのだから、そろそろ見つかるはず」と感じるかもしれませんが、各試行が独立で成功確率が一定であるかぎり、過去の結果は未来に影響しません。この感覚はギャンブラーの誤謬と呼ばれる代表的な認知の歪みです。
無記憶性の確認
P(X>n) を求めます。X>n は「最初の n 回がすべて失敗」を意味するので、
P(X>n)=(1−p)n
条件付き確率の定義より、
P(X>s+t∣X>s)=P(X>s)P(X>s+t かつ X>s)
X>s+t であれば当然 X>s も満たすため、分子は単に P(X>s+t) となります。
=P(X>s)P(X>s+t)=(1−p)s(1−p)s+t=(1−p)t=P(X>t)
指数分布との対比
指数分布の単元で「連続型分布の中で無記憶性を持つのは指数分布だけ」と学びました。
実は、離散型分布の中で無記憶性を持つのは幾何分布だけです。
| 幾何分布 | 指数分布 |
|---|
| 型 | 離散型 | 連続型 |
| 確率変数 | 初めて成功するまでの試行回数 | 次の事象が起きるまでの待ち時間 |
| 無記憶性 | P(X>s+t∣X>s)=P(X>t) | P(X>s+t∣X>s)=P(X>t) |
| パラメータ | 成功確率 p | 発生率 λ |
| 期待値 | 1/p | 1/λ |
どちらも「各試行(時点)が独立で、成功(発生)の確率が一定」という同じ前提に基づいています。幾何分布は離散的に数える場合、指数分布は連続的に時間を測る場合に使い分けます。
まとめ
幾何分布 Geo(p) は、成功確率 p のベルヌーイ試行を繰り返したとき、初めて成功するまでの試行回数を表す離散分布です。
P(X=k)=(1−p)k−1p
期待値は p1、分散は p21−p です。
代表的な特徴は無記憶性で、過去の失敗回数が今後の確率に影響しません。離散型分布の中で無記憶性を持つのは幾何分布だけであり、これは連続型における指数分布と対をなす性質です。
使う前に 3つの前提(2択・成功確率一定・独立) を確認してください。