p値は何を測っていて、何を測っていないか
p値が実際に測っていることと、測っていないことを明確に区別します。検定結果の解釈で陥りやすい誤解を避け、正しく向き合う技術を学びます。
できるようになること
- p値が「何を測っていて、何を測っていないか」を正確に説明できる
- p-ハッキングが統計的にどういう意味を持つかを理解する
- 棄却できなかった結果に対して、実務的に誠実な判断ができる
有意差が出なかった。どうする?
検定をした。p ≥ 0.05 でした。
半年かけて集めたデータ、時間をかけて準備した実験。それでも有意差が出なかったとき、「この研究には意味がなかった」ということになるのでしょうか。
それとも、分析の仕方を変えて有意差がでるまで検定を繰り返せばいいのでしょうか。
この問いに正しく向き合うには、p値がそもそも何を測っていて、何を測っていないかを理解する必要があります。
p値の正体
「仮説検定の考え方」と「検定の誤りと解釈」で、p値の定義と代表的な誤解をすでに学びました。この単元では、定義をもう一段掘り下げます。
p値は「裾面積」である
p値の定義を視覚的に言い換えると、次のようになります。
- 帰無仮説のもとで検定統計量がどのような分布に従うかを描く
- 実際に観測された統計量の位置に印をつける
- そこから先(より極端な方向)の面積を測る
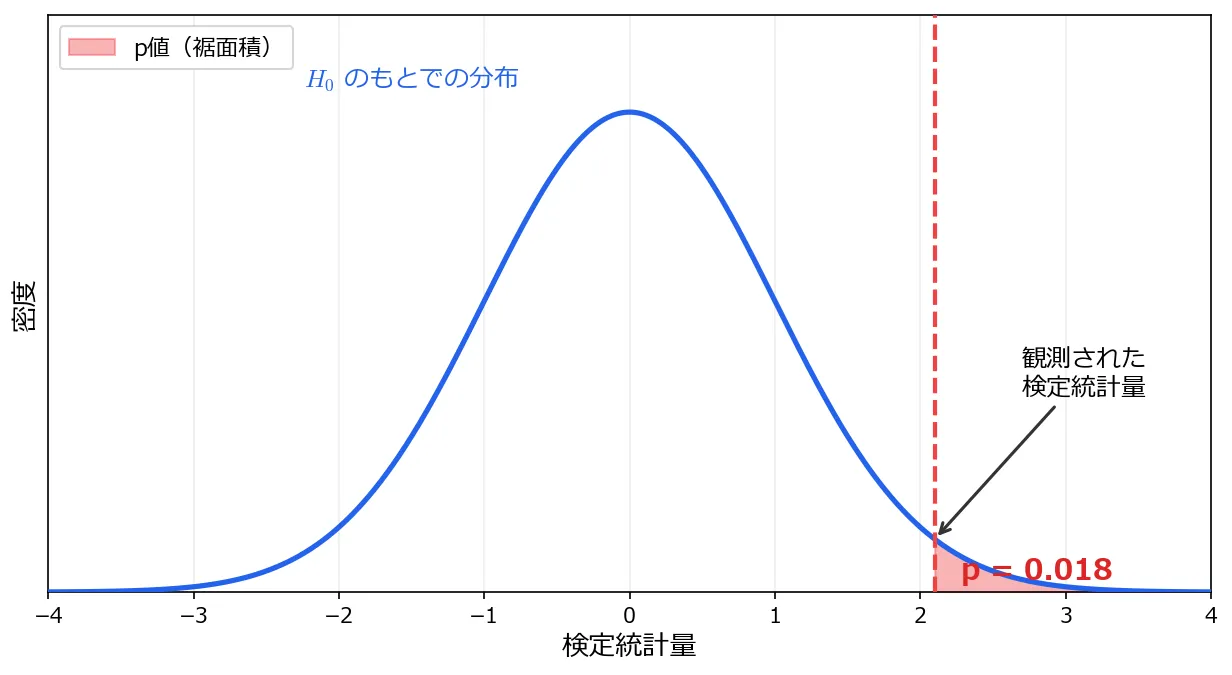
この面積がp値です。
面積が小さいとは、帰無仮説のもとでは「端の方にいる」ということです。端の方にいるなら、帰無仮説が正しいという前提そのものが怪しい。これが棄却の論理です。
p値が教えてくれないもの
p値は帰無仮説のもとでの裾面積を測っています。
つまり、p値が教えるのは「帰無仮説とデータの相性」だけです。以下のことは測っていません。
| p値が教えないこと | なぜ教えないか |
|---|---|
| 効果の大きさ | p値にはサンプルサイズが混ざっている。同じ効果でもnが変わればp値も変わる |
| 帰無仮説が正しい確率 | p値は「帰無仮説が正しいとしたら」の計算で帰無仮説が正しい確率は別の話(ベイズの話)である |
| 結果の再現性 | p = 0.04 でも、同じ実験を繰り返したら次はp = 0.30 になることがある |
特に「再現性」は見落とされがちです。p値は標本から計算される値であり、標本が変われば値も変わります。p = 0.04 という結果は、「次も同じ結果が出る」ことを保証しません。
同じp値でも意味が違う
ここが最も重要な点です。
2群の平均差を検定するとき、検定統計量はおおまかに次の形をしています。
分子は「効果の大きさ」(2群の差)、分母は「標準誤差」です。 が分母の中にあるため、nを大きくすれば、効果がどんなに小さくても z は大きくなり、p値は小さくなります。
この構造から、同じ p = 0.03 でも中身がまったく違う2つの結果が生まれます。
結果1:新薬の臨床試験。n = 50,000。体温の平均低下が 0.02°C。p = 0.03。
結果2:新しいリハビリ法の試験。n = 30。歩行速度の平均改善が 25%。p = 0.03。
結果1は、 という巨大な値が分母を押しつぶすことで、0.02°C という微小な差でも z が大きくなり、有意になっています。体温が 0.02°C 下がったところで患者にとっての実感はありません。
結果2は、 と小さいため、p = 0.03 になるには分子(効果)自体が大きい必要があります。歩行速度が 25% 改善すれば、日常生活に明確な変化があります。
ただし、サンプルサイズが小さい状況で「たまたま有意になった」場合、観測された効果(ここでは25%)は真の効果よりも過大に見積もられている可能性があります。小標本で有意になった結果ほど、効果の解釈には慎重さが必要です。
サンプルサイズは大きいほど良いと思われがちですが、p値の観点ではそうとは限りません。nが十分に大きければ、ほとんどすべての差が有意になります。そうなると「有意かどうか」はもはや有用な問いではなくなり、「どれぐらい大きな効果か」が本当に知りたいことになります。nが大きい状況ほど、p値だけでなく効果量を併せて見ることが重要です。
p値は「効果の大きさ」と「サンプルサイズ」が混ざった1つの数字です。p値だけを見ても、どちらがどれだけ貢献しているかは分かりません。
有意にしたいとき、何をしてしまうか
有意差が出なかったとき、「分析のやり方を変えれば有意になるのでは」と考えたことはないでしょうか。この行動には、統計的な落とし穴があります。
p-ハッキングとは
**p-ハッキング(**p-hacking)とは、有意な結果が出るまで分析方法やデータの扱いを操作することです。意図的な不正から無意識の判断まで、グラデーションがあります。
| 行動パターン | 具体例 |
|---|---|
| 検定方法を変える | t検定で有意にならなかったので、ノンパラメトリック検定に切り替える |
| サンプルを追加する | 有意にならなかったので、10人追加してもう一度検定する |
| アウトカムを変える | 主要評価項目で有意にならなかったので、別の指標を「主要」と言い換える |
| サブグループを探す | 「20代女性に限ると有意だった」と報告する |
| 外れ値を除外する | 有意にならない原因をつくっているデータ点を分析から除く |
どの行動も、1つだけなら「妥当な分析判断」の場合があります。統計的な問題が生じるのは、有意にならなかったという結果を見てから、有意にするために行動を選んでいる点です。
第1種の過誤の膨張
なぜこれが問題なのか。統計的に説明します。
有意水準 で検定すると、帰無仮説が正しいとき、偶然だけで棄却してしまう確率は 5% です。
しかし、1つのデータに対して検定を 回行うと、少なくとも1回は偶然で有意になる確率は増加します。各検定が独立な場合:
実際のp-ハッキングでは検定間に相関があるため、この式の計算結果と厳密には一致しませんが、第1種の過誤率が膨張するという本質は変わりません。 のとき:
| 検定回数 k | 偶然で1回以上有意になる確率 |
|---|---|
| 1回 | 5.0% |
| 5回 | 22.6% |
| 10回 | 40.1% |
| 20回 | 64.2% |
20回試せば、帰無仮説が正しくても3回に2回は「有意な結果」が出ます。
p-ハッキングは、有意水準のもとで保証されている第1種の過誤率を、本人が気づかないまま膨張させます。報告されたp値の額面は、もはや信頼できません。
有意にならなかったとき、何ができるか
ここまで、「有意にしたい」ときに何が起きるかを見ました。では、p-ハッキングに走らず、有意でなかった結果をそのまま受け止めたとき、そこから何が読み取れるのでしょうか。
「差がないこと」を主張していない
「検定の誤りと解釈」で学んだように、p値が有意水準以上であることは「差がない」ことを意味しません。「帰無仮説を棄却する十分な証拠がなかった」だけです。
この「証拠不十分」には、大きく2つの原因がありえます。
- 本当に差がない(または非常に小さい)
- 差はあるが、検出力が足りなかった(サンプルサイズが小さい、データのばらつきが大きいなど)
どちらなのかを判断する材料としては、検出力、効果量、信頼区間などがあります。
検出力で振り返る
**検出力(**power)は、対立仮説が正しいとき、正しく帰無仮説を棄却できる確率です。( は第2種の過誤の確率)で表されます。
有意にならなかったとき、実験計画の段階で想定していた効果の大きさに基づく検出力がどれぐらいだったのかを確認すると、結果の解釈が変わります。
例:「このリハビリ法で歩行速度が10%改善する」と想定して設計した実験の検出力が 0.30 だった場合、仮に10%の改善が本当にあったとしても、30% の確率でしか検出できなかった設計です。有意にならなかったのは「差がない」からではなく、「検出する力が足りなかった」可能性が高いことになります。
検出力は、実験の前に「検出したい効果の大きさ」を決めて計算するものです。実験後に観測された結果から計算した「事後検出力」は、p値を別の数字に変換しただけであり、新しい情報をもたらしません。
ここで「nが足りなかったなら、もっと増やせばいい」と考えるかもしれません。
しかし、前のセクションで見たように、nが大きすぎると実質的に意味のない差まで有意になってしまいます。nは大きければ良いのではなく、検出したい効果の大きさに見合ったnを事前に設計することが重要です。nの設計については、別の単元で詳しく解説します。
効果量を報告する
p値が有意でなくても、**効果量(**effect size)は報告できます。効果量とは、観測された効果の大きさを示す指標です。分析の種類によってさまざまな指標があります。
- 平均差:2群の平均値の差(例:治療群と対照群の差が5点)
- 相関係数:2変数の直線的な関係の強さ(相関係数の単元で学びました)
- オッズ比:2群の比率の比較(例:治療群は対照群の2倍改善しやすい)
これらはいずれもp値とは独立に効果の大きさを示します。p値が有意でなくても、効果量を報告することで「どれぐらいの差が観測されたか」を伝えられます。
信頼区間を添える
効果量に信頼区間を添えると、その推定の不確実性が見えます。
例:「2群の平均差は5点(95%信頼区間 [-1, 11])。p = 0.10 で統計的に有意ではなかった」
この報告からは、以下のことが読み取れます。
- 平均差は5点あり、効果としては小さくない
- 信頼区間は 0 をまたいでいるが、区間の大部分は正の側にあり、差がある可能性は残っている
- サンプルサイズを増やせば有意になる可能性がある
p値は「棄却する/しない」の二択しか提供しませんが、信頼区間は効果がどの範囲にありそうかを連続的に示します。幅が広ければ「まだよく分からない状態」、狭ければ「かなり絞り込めた状態」です。「有意ではなかった」という結論に、「でも効果はこのあたりにありそうだ」という情報を添えることで、次の研究やビジネス判断に活かせます。
グレーゾーンをどう渡るか
ここまで、「有意にしたいとき」と「有意にならなかったとき」の両側を見ました。この2つは、ある意味で両極端な状況です。実務で多いのは、その間にあるケースです。
完全な黒(データ捏造)と完全な白(事前登録どおりの一発勝負)の間には、広いグレーゾーンがあります。
- 外れ値の除外基準を「結果を見た後で」決めた
- 有意でなかったので、追加でサブグループ分析を行った
- 複数の分析法を試したが、有意だったものだけを論文に書いた
これらは不正とまでは言えませんが、第1種の過誤率を膨張させる行為です。
3つの軸で判断する
自分の分析がグレーゾーンのどこにいるかを把握するために、次の3軸で振り返ります。
軸1:自覚
「事後的な判断を行った」という自覚があるかどうか。問題が大きくなるのは、自覚なく行われた場合です。自覚があれば、次の2つの軸で影響を制御できます。
軸2:影響の把握
「もし別の判断をしていたら、結論は変わるか」を確認すること。外れ値を除外した場合、「除外しなかった場合」も計算して結果を比べます。結果が変わらなければ、判断の影響は小さいと言えます。これは**感度分析(**sensitivity analysis)の発想です。
軸3:透明性
何をやったかを記録し、開示できる状態にあること。「他の分析も試したが有意ではなかった」「外れ値を除外した基準と理由はこうだった」と書けること。結果を隠していないこと。
この3軸は正当性の条件ではありません。すべて満たしていても第1種の過誤率は膨張しています。しかし、「何をしたか」が透明に記録されていれば、読み手はその上で判断できます。
検定レポートチェックリスト
以下の4項目は、自分の検定結果をセルフチェックし、報告するときの道具です。
| 項目 | 確認すること |
|---|---|
| 事前決定 | 検定方法・有意水準・サンプルサイズはデータを見る前に決めたか |
| 全数報告 | 実施したすべての検定を(有意でなかったものも含めて)報告しているか |
| 効果量 | p値だけでなく、効果の大きさ(および信頼区間)も提示しているか |
| 感度 | 外れ値の除外基準や分析の選択を変えたとき、結論が変わらないか確認したか |
このチェックリストに1つでも「いいえ」がある場合は、報告に注記を加えることを検討してください。すべて「はい」と言えるなら、その検定結果の信頼性は相当に高いといえます。
まとめ
p値は、帰無仮説のもとでの裾面積を測っています。効果の大きさも、帰無仮説が正しい確率も、結果の再現性も測っていません。
「有意にしたい」ときに分析を操作すると(p-ハッキング)、報告上のp値は額面どおりの意味を失います。検定を繰り返すたびに第1種の過誤率は膨張し、20回試せば帰無仮説が正しくても3回に2回は有意になります。
「有意にならなかった」ときは、検出力、効果量、信頼区間を確認しましょう。差がないのではなく、検出する力が足りなかっただけかもしれません。
実務のグレーゾーンでは、自覚・影響の把握・透明性の3軸で自分の分析を振り返り、検定レポートチェックリスト(事前決定・全数報告・効果量・感度)で報告の信頼性を担保してください。
p値は判断のための1つの道具です。道具の使い手の誠実さが、結論の信頼性を決めます。