指数分布
次の事象が起きるまでの待ち時間をモデル化する指数分布を学びます。ポアソン分布との関係や無記憶性という特徴的な性質を解説します。
できるようになること
- 指数分布の前提を確認し、使えるかどうかを判断できる
- と を使って確率を計算できる
- 無記憶性の意味と、それが成り立つ条件を説明できる
次の事象が起きるまでの待ち時間
コールセンターに次の電話がかかってくるまでの時間、機械が故障するまでの時間。
こうした「次の事象が起きるまでの待ち時間」を表す確率分布の一つが**指数分布(**exponential distribution)です。
ただし、どんな待ち時間でも指数分布に従うわけではありません。無記憶性という特別な性質を持つ場合に限られます。
コールセンターや機械の故障は、この無記憶性が成り立ちやすい典型例のため、指数分布がよく使われます。
ポアソン分布では「単位時間あたり何回起こるか」を扱いました。指数分布は「次の事象が起きるまで何分待つか」という、裏返しの問いに答える分布です。
指数分布とは何か
確率変数 がパラメータ の指数分布に従うとき、次のように書きます。
ここで、
- (待ち時間は負にならない)
- (単位時間あたりの発生率)
は単位時間あたりの発生率で、単位は「回/時間」です。
平均待ち時間は (単位が逆)になります。
- 1時間あたり平均3件の電話がかかってくる → (/時間)
- 1日あたり平均0.1回の故障が起きる → (/日)
指数分布が成り立つための前提
指数分布を使うためには、次の前提が必要です。
| 前提 | 意味 |
|---|---|
| 1. 事象が独立 | ある事象の発生が、次の事象の発生に影響しない |
| 2. 発生率 が一定 | 単位時間あたりの発生率が、どの時間帯でも変わらない |
| 3. 開始点が明確 | 「次の事象までの待ち時間」をどこから測るかが明確に定義されている |
これらの前提が成り立つとき、指数分布は無記憶性という特別な性質を持ちます。
確率密度関数
指数分布の確率密度関数は次の式で表されます()。
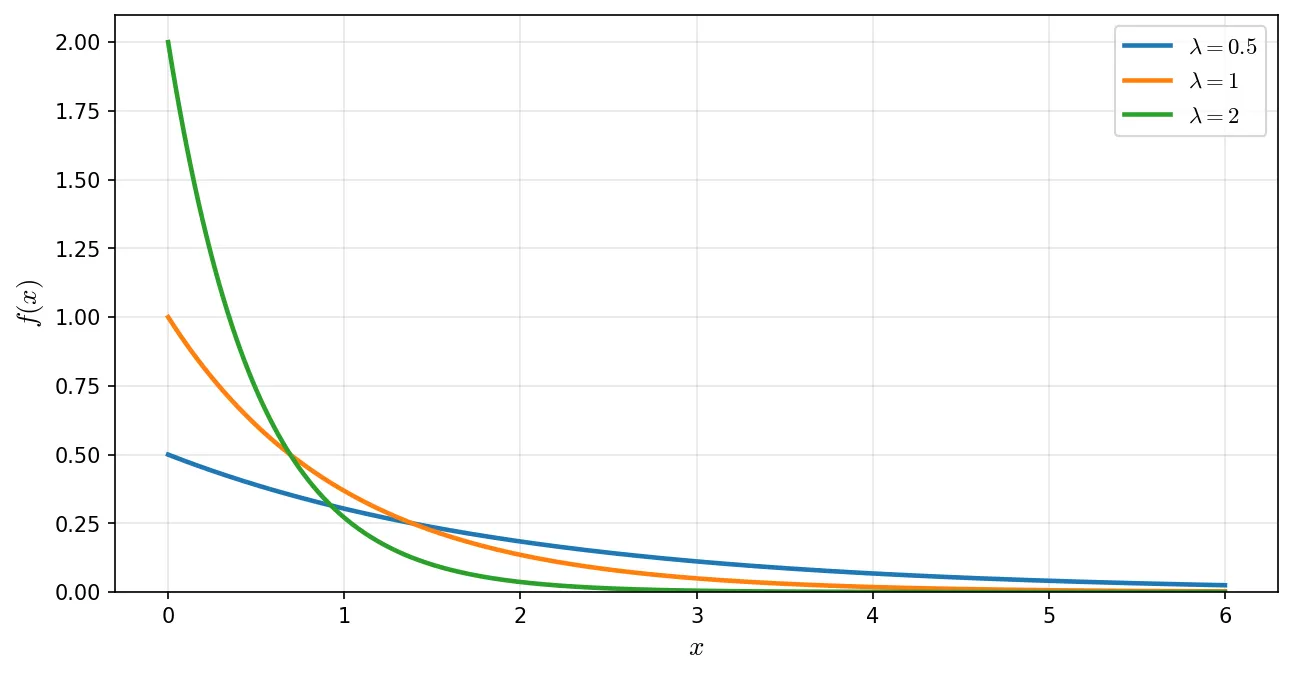
グラフは で最も高く、 が大きくなるにつれて指数的に減少していきます。 付近で確率密度が大きく、短い区間での確率が大きくなりやすいという特徴があります。
ポアソン分布との関係
ポアソン分布と指数分布は密接に関係しています。
- ポアソン分布:単位時間あたりの発生回数を表す(離散型)
- 指数分布:次の発生までの待ち時間を表す(連続型)
同じ前提(独立・発生率一定) のもとで、回数がポアソン分布、待ち時間が指数分布に従います。
両者の関係は次のように理解できます。「待ち時間が より長い」という事象は、「時間 までに事象が0回しか起きない」という事象と同じです。
これがポアソン分布から指数分布の式が導かれる理由です。
確率の計算
「待ち時間が 以下になる確率」は分布関数で求められます。
逆に「待ち時間が より長い確率」は、
例:(/時間)のとき、次の電話が20分以内にかかってくる確率は、
20分 = 時間 = 時間なので、
無記憶性という特徴
指数分布の最も特徴的な性質が無記憶性です。
「すでに 分待った後、さらに 分以上待つ確率」は、「最初から 分以上待つ確率」と同じになります。
具体例:10分待っても電話が来なかった。「さらに5分以上待つ確率」は、最初から「5分以上待つ確率」と変わりません。
これは最初は意外に感じるかもしれません。「もう10分も待ったんだから、そろそろ来るはず」と思いがちですが、指数分布では過去の待ち時間は未来の確率に影響しません。
無記憶性が成り立つのは、各事象が独立に発生し、発生率 が一定である場合です。実務では、この前提が本当に成り立っているかを確認する必要があります。
無記憶性と指数分布
連続型確率分布の中で、無記憶性を持つのは指数分布だけです。
つまり、「ある現象が無記憶性を持つ」とわかれば、その待ち時間は指数分布に従うと判断できます。逆に、無記憶性が成り立たないなら、指数分布ではありません。
この性質は指数分布を使ってよいかを判断する重要な基準になります。
無記憶性が成り立たない例
コールセンターや機械の故障は無記憶性が成り立ちやすい状況ですが、常に成り立つわけではありません。前提を確認せずに使うと、実態とずれることがあります。
機械の寿命(劣化がある場合)
部品が劣化するため、使用年数が長いほど故障率は上がります。例として、新品で10%だった1年以内の故障確率が、5年使った機械では30%、10年使った機械では50%のように増加します。
このような「過去の使用が未来に影響する」状況では、無記憶性は成り立ちません。
時間帯による変動がある場合
が時間帯で変わる場合(昼間は /時間、夜間は /時間など)、発生率が一定という前提が成り立たなくなります。11時と23時では次の電話が来る確率が明らかに違うため、無記憶性は成り立ちません。
期待値と分散
指数分布 の期待値と分散は、
- 期待値:
- 分散:
例:1時間あたり平均3件の電話(/時間)なら、次の電話までの平均待ち時間は 時間 = 20分です。
期待値が になるのは直感的にも納得できます。「単位時間あたり 回」なら「1回あたり 時間」です。
補足:期待値の導出
期待値は定義に従って計算できます。
部分積分(, )を使うと、
のとき (指数関数の減少が支配的)より、第一項は0になります。
まとめ
指数分布 は、次の事象が起きるまでの待ち時間を表す連続分布です。
パラメータ は単位時間あたりの発生率で、期待値は になります。
最も重要な性質は無記憶性で、過去の待ち時間が未来の確率に影響しません。連続型分布の中で無記憶性を持つのは指数分布だけです。
無記憶性は事象が独立に発生し、発生率が一定の場合に成り立ちます。劣化や時間帯による変動がある場合は成り立たないため、前提の確認が重要です。