単回帰と予測
最小二乗法で直線を当てはめてデータから予測する単回帰分析を学びます。回帰直線の求め方、決定係数による当てはまりの評価を扱います。
できるようになること
- 散布図から回帰直線を引く意味を説明できる
- 最小二乗法で回帰係数(傾きと切片)を計算できる
- 決定係数 の意味を説明できる
広告費を増やせば売上は伸びるか?
ある会社が過去8か月の広告費(万円)と売上(万円)を記録しました。
| 月 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 広告費 | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 |
| 売上 | 120 | 150 | 160 | 200 | 210 | 250 | 260 | 300 |
散布図を描くと、広告費が増えるほど売上も増える傾向が見えます。直線を引きたくなりますが、どの直線が「最良」でしょうか?
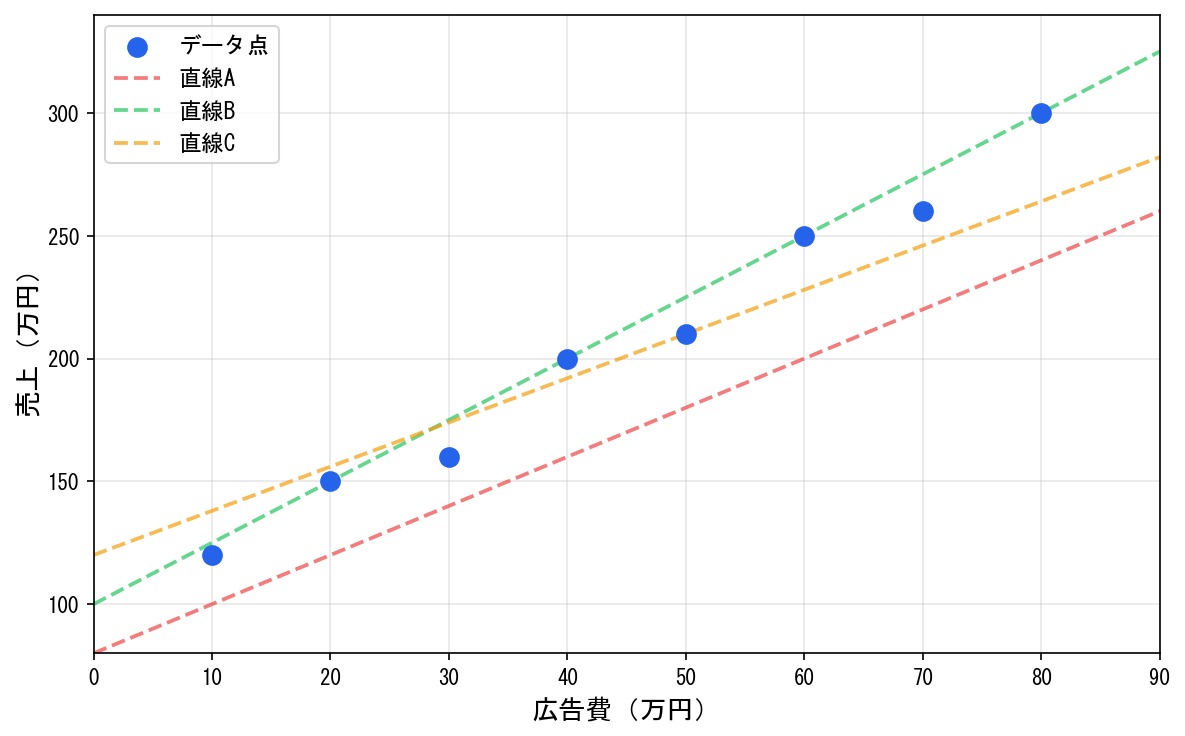
相関係数を計算すれば「関連が強い」ことはわかりますが、
- 広告費を90万円にしたら売上はいくらになるか?
- 広告費が1万円増えると売上は何万円増えるか?
という「予測」の問いには、相関係数だけでは答えられません。
この問いに答えるために、データに直線を当てはめて予測に使うのが**回帰分析(**regression analysis)です。
回帰直線のモデル
散布図に直線を引くことを考えます。直線は次のように書けます。
- : を与えたときの予測値(ハットは「予測」を意味する)
- :**回帰係数(**傾き)— が1単位増えると がどれだけ変わるか
- :切片 — のときの の値
しかし、無数にある直線のうち、どれが「最良」でしょうか?
最小二乗法
残差とは
データ点 に対して、直線上の値 を予測値といいます。実際の値との差、
を**残差(**residual)といいます。残差は「直線からのズレ」を表します。
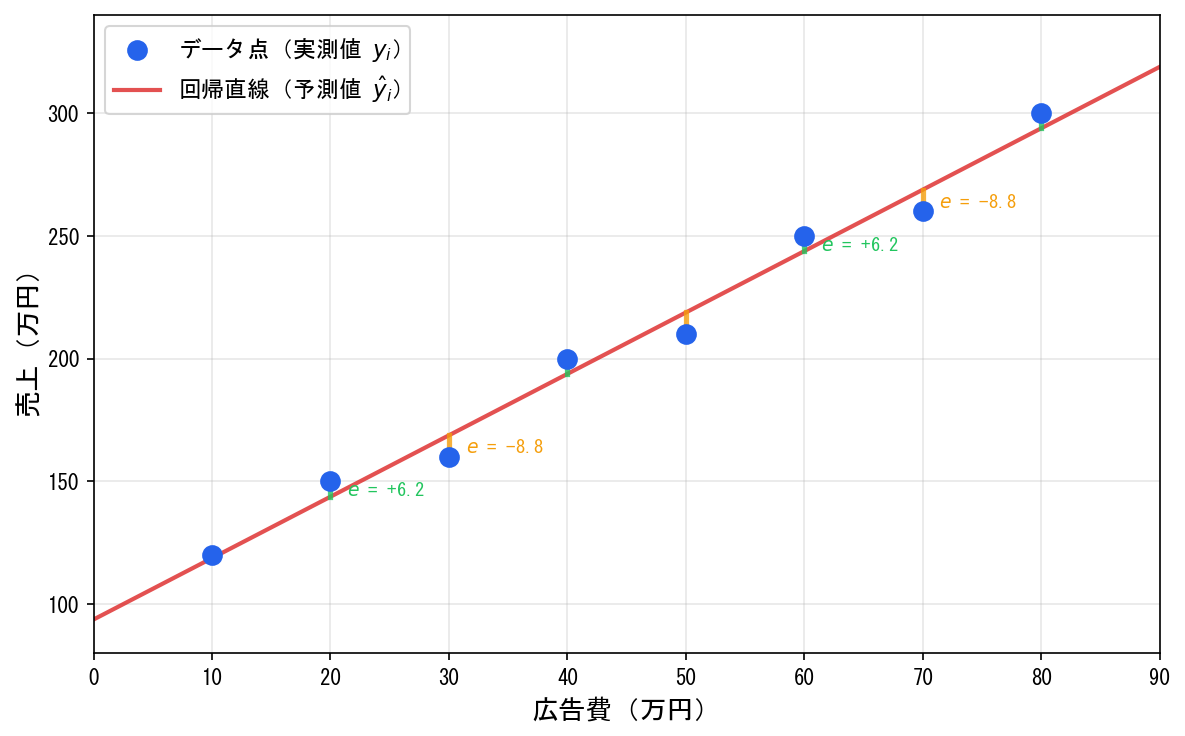
残差の二乗和を最小にする
「最良の直線」とは、すべてのデータ点からのズレができるだけ小さい直線です。残差をそのまま足すと正負が打ち消し合うため、二乗して正の値にしてから合計します。この**残差の二乗和(**sum of squared residuals)を最小にします。
この を最小にする と を求める方法を**最小二乗法(**method of least squares, OLS)といいます。
と の推定方法は他にもあります(たとえば残差の絶対値の和を最小にする方法)。その中で最小二乗法(OLS)が広く使われるのは、微分による計算が容易であること、そして大きなズレに対してより重いペナルティを与える特性があるためです。
回帰係数の公式
を と でそれぞれ偏微分して0とおくと、次の連立方程式(正規方程式)が得られます。
これを , について解くと、
ここで、
- : と の偏差積和
- : の偏差平方和
公式の分子と分母をそれぞれ (または )で割ると、分子は と の共分散、分母は の分散になります。つまり = 共分散 / の分散 です。
は「回帰直線が必ず を通る」ことを意味します。データの中心点を通るように直線が決まる、と理解してください。
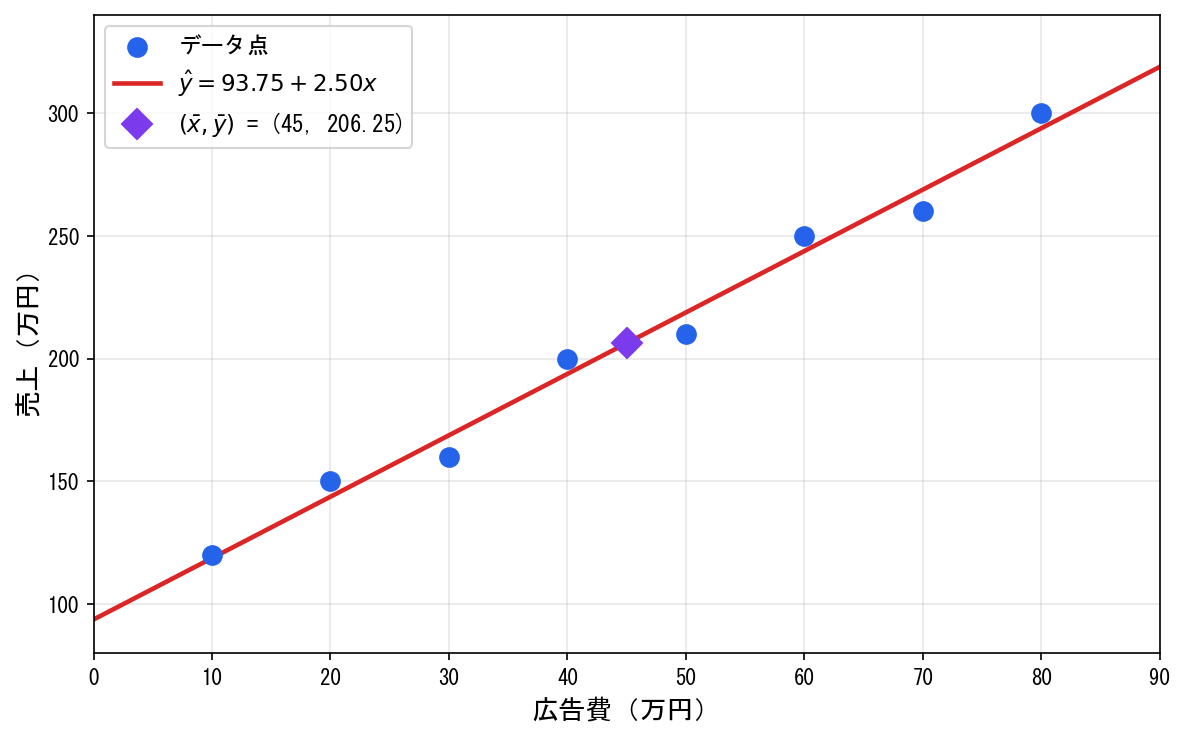
例題の計算
先ほどのデータで回帰直線を求めましょう。
基本統計量:
偏差積和と偏差平方和:
回帰係数:
回帰直線:
結果の解釈
- 傾き :広告費を1万円増やすと、売上は平均して2.50万円増えると予測される
- 切片 :広告費が0万円のときの売上の予測値だが、データの範囲外(外挿)のため実務的な意味は薄い
予測
広告費が90万円のときの売上の予測値は、
データの範囲外(この例では = 10〜80 の外)への予測を**外挿(**extrapolation)といいます。回帰直線はデータの範囲内ではよく当てはまりますが、範囲外では関係が変わる可能性があるため、外挿は慎重に行う必要があります。
決定係数
回帰直線がデータにどれだけ当てはまっているかを測る指標が決定係数 (coefficient of determination)です。
変動の分解
の変動(ばらつき)は次のように分解できます。
- 全変動 : の全体的なばらつき
- 回帰変動:回帰直線で説明できるばらつき
- 残差変動:回帰直線では説明できないばらつき
この分解が成り立つのは、最小二乗法の条件により、展開時に現れる交差項 が 0 になるためです。
の定義
- :すべてのデータ点が直線上にある(完全な当てはまり)
- :直線で のばらつきをまったく説明できない
- の値を取る
相関係数との関係
単回帰の場合、決定係数は相関係数の二乗に等しくなります。
先ほどの例について相関係数を求めると(「相関係数」の単元で学んだ公式 を使います)、 なので です。つまり、売上のばらつきの約 98.6% が広告費で説明できます。
残差の確認
回帰分析を行ったあとは、残差のパターンを確認することが重要です。
| 月 | (実測) | (予測) | ||
|---|---|---|---|---|
| 1 | 10 | 120 | 118.75 | +1.25 |
| 2 | 20 | 150 | 143.75 | +6.25 |
| 3 | 30 | 160 | 168.75 | −8.75 |
| 4 | 40 | 200 | 193.75 | +6.25 |
| 5 | 50 | 210 | 218.75 | −8.75 |
| 6 | 60 | 250 | 243.75 | +6.25 |
| 7 | 70 | 260 | 268.75 | −8.75 |
| 8 | 80 | 300 | 293.75 | +6.25 |
残差にパターン(たとえば U 字型の曲線)が見える場合、直線では捉えきれない関係がある可能性を示唆します。この例では残差が正負に散らばっており、大きな系統的パターンは見られません。
よくある誤解
「 が高ければモデルが正しい」
が高くても、モデルが現象を正しく捉えているとは限りません。直線以外の関係(曲線など)がある場合でも が高くなることがあります。また、 が高いことは「 が の原因である」という因果関係を意味しません。
「回帰直線の外挿は信頼できる」
データの範囲内(内挿)での予測は比較的信頼できますが、範囲外(外挿)では関係が変わる可能性があります。広告費0〜80万円のデータで100万円を予測するのは外挿であり、注意が必要です。
「残差が小さい = モデルが正しい」
残差が小さくても、モデルが現象を正しく説明しているとは限りません。残差に系統的なパターンがないかどうか(残差プロット)を確認することが重要です。
まとめ
回帰分析は、2変数の関係を直線で表現し、予測に使う手法です。回帰係数 は「 が1単位増えると がどれだけ変わるか」を表し、切片 から回帰直線が定まります。この直線は を必ず通ります。
決定係数 は回帰直線の当てはまりの良さを0〜1で表し、単回帰では (相関係数の二乗)に一致します。予測には使えますが、因果関係の証明ではなく、外挿にも注意が必要です。
この単元では手元のデータに対する直線の当てはめ(記述的なアプローチ)を扱いました。求めた回帰係数 が偶然の産物でないかを検定したり、予測値に信頼区間をつけたりする推測統計的なアプローチは、「重回帰モデルの基礎」以降で学びます。